马拉车
马拉车是一个能在线性时间复杂内计算字符串的最长回文子串长度的算法。
回文字符串是指从左往右读跟从右往左读都一样的字符串,比如 aba,cddc。
要算出一个字符串里最长回文子串的长度,我们要先知道怎样找出一个回文子串。
以 aba,cddc 为例,可以看到回文中的字符,一定是以某个位置为中心,左右对称的。
假设 str 是回文字符串, mid 是回文中心,i 是大于 0 且不大于 mid 的整数。
对每一个 i 会有:
str[mid + i] === str[mid - i]
只是这个中心与回文字符串的长度是奇数还是偶数有关。
如果长度是奇数(len),那这个中心就是 Math.floor(len / 2),上面的等式改写为:
str[Math.floor(len / 2) + i] === str[Math.floor(len / 2) - i]
如果长度是偶数(len),中心会有两个,分别是 len / 2 和 len / 2 - 1 ,这时上面的等式改写为:
str[len / 2 + i] === str[len / 2 - 1 - i]
求一个字符串里最长回文子串的长度的一般解法,就是遍历字符串,假设当前正在遍历的字符串位置是回文中心,尝试对比以它为中心左右对称的字符,如果它们相等,回文子串长度增加 2 ,否则移动回文中心到下一个位置。
每一个字符串位置有可能是奇数回文子串的中心,也有可能是偶数回文子串靠左边的中心。
const find = (str) => {
const len = str.length;
let max = 0
const findOdd = (mid) => {
let j = 1
let lenOdd = 1
while(mid - j >= 0 && mid + j < len) {
if(str[mid - j] === str[mid + j]) {
lenOdd += 2
} else {
break;
}
j++
}
return lenOdd
}
const findEven = (mid) => {
let lenEven = 0
let left = mid
let right = mid + 1
while(left >= 0 && right < len) {
if(str[left] === str[right]) {
lenEven += 2
} else {
break;
}
left--
right++
}
return lenEven
}
for(let i = 0; i < len; i++) {
max = Math.max(max, findOdd(i), findEven(i))
}
return max
}
可以看到这种解法有两重循环,所以时间复杂度是 O(n^2),虽然不算太高,但是也不低了。
抛开时间复杂度,单说算法实现时要分别处理两种情况,就有点复杂。有没有一种处理方式,可以屏蔽字符串长度的奇偶差异,然后用同一种算法处理呢?比如把字符串长度统一成奇数(或者偶数)再处理?
还真的有。我们可以用一个相同的字符分隔原字符串中各个字符,再往一头一尾放进这个字符。
这个字符是什么不重要,下文以 # 为例。
如果原字符串长度为奇数,因为会多出偶数个新字符,奇数与偶数相加,处理之后还是奇数。如 aba 变为 #a#b#a#
如果原字符串长度为偶数,因为会多出奇数个新字符,偶数与奇数相加,处理之后是奇数。如 cddc 变为 #c#d#d#c#
这样处理并不会将一个原本是回文的字符串变成不回文,只会增大回文长度到原来的两倍再加一,而且回文中心一定是在奇数位置。这样算法可以改写为:
const find = (str) => {
let len = str.length;
let max = 0;
const newStr = ['#']
for(let i = 0; i < len; i++) {
newStr.push(str[i])
newStr.push('#')
}
len = newStr.length
const findOdd = (mid) => {
let j = 1
let lenOdd = 1
while(mid - j >= 0 && mid + j < len) {
if(newStr[mid - j] === newStr[mid + j]) {
lenOdd += 2
} else {
break;
}
j++
}
return lenOdd
}
for(let i = 0; i < len; i++) {
max = Math.max(max, findOdd(i))
}
return Math.floor(max / 2)
}
这样处理后,算法还是有两重循环,时间复杂度还是 O(n^2),跟前一个算法相比,只是少写了几行代码。
很多时候,算法时间复杂度高是因为我们做了很多重复计算,如果高复杂度真的是因为这种情况,就可以用额外的空间记录之前的计算结果,避免重复计算。
说到底就是以空间换时间。
我们可以看看在上面的算法有没有重复计算。
以 #a#b#a# 为例,
我们的算法计算以第一个 a 为中心的回文长度,以 b 为中心的回文长度,最后是第二个 a 为中心的回文长度。最终选出其中最长的一个。
其实以第二个 a 为中心的回文长度可以不用计算,可直接由前面两个结果以及自身的位置推算出来。(只是非常难想到)
原因在于两个 a 的回文子串都包含在 b 的回文子串之内,而且刚好是以 b 为中心左右对称。
假设我们能找到一个回文子串,并且知道所有位于这个回文子串中心左侧字串的回文信息,那么位于其右侧字串的回文信息就可以推算出来。
这里分两种情况。
情况一如下图,如果以第一个 a 为中心的回文子串的最左侧的字符索引大于(或等于)以 b 为中心的回文子串的最左侧字符索引,也就是说以第一个 a 为中心的回文子串长度小于(或等于)以 b 为中心的回文子串长度的一半减一,那么以第二个 a 为中心的回文子串长度就等于以第一个 a 为中心的回文子串长度。
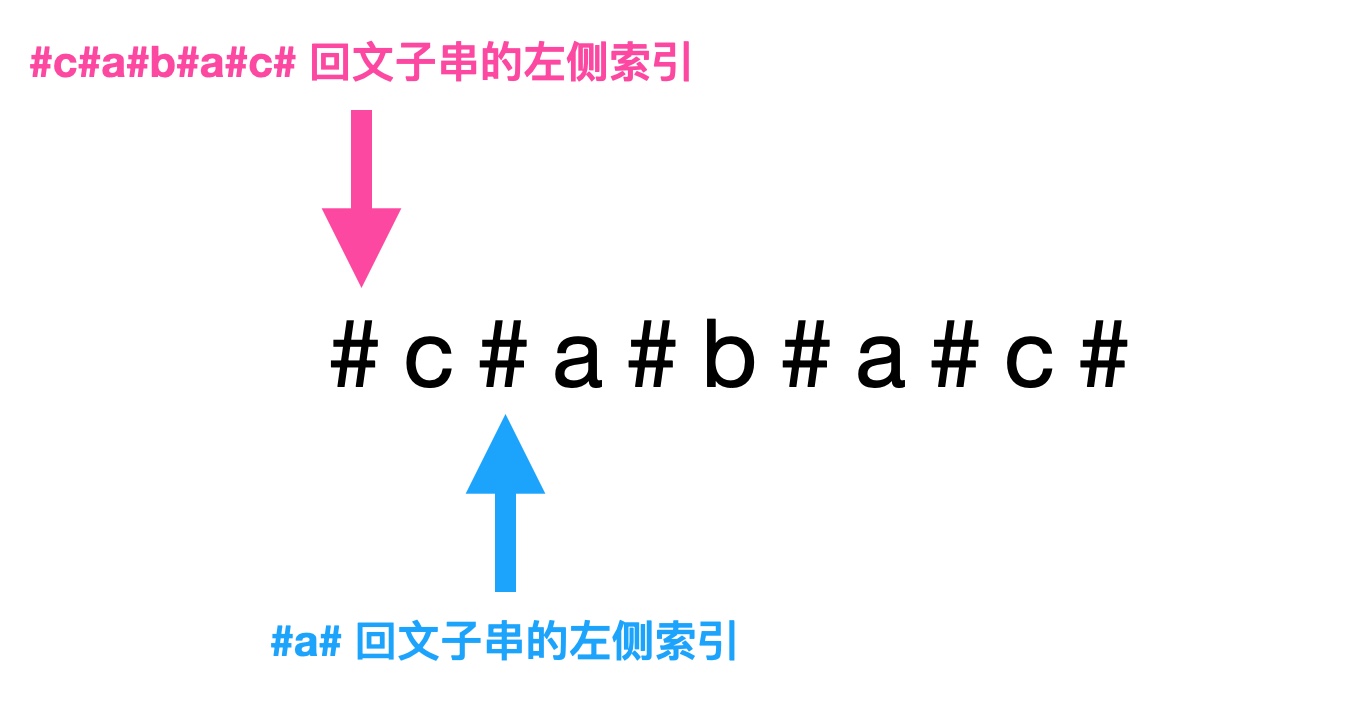 manacher situation 1
manacher situation 1
情况二如下图,如果以第一个 a 为中心的回文子串的最左侧的字符索引小于以 b 为中心的回文子串的最左侧字符索引,也就是说以第一个 a 为中心的回文子串长度大于以 b 为中心的回文子串长度的一半减一。
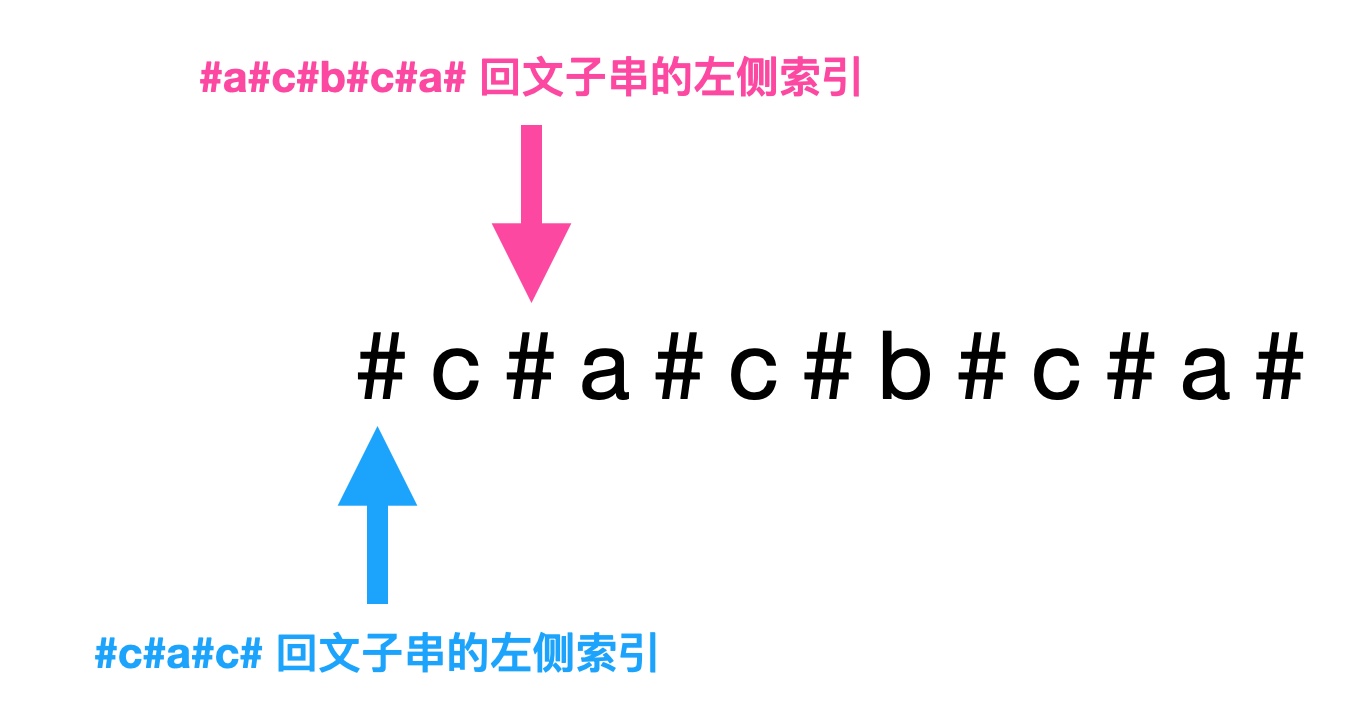 manacher situation 2
manacher situation 2
那么以第二个 a 为中心的回文子串长度就等于第一个 a 的位置索引减去以 b 为中心的回文子串的最左侧字符索引再加一。
因为两个 a 都包含在 b 的回文字符串之内,且以 b 为中心对称,以第二个 a 为中心的回文子串长度等于以 b 为中心的回文子串的最右侧字符索引减去第二个 a 的位置索引再加一。
在计算的时候不用去判断到底遇到两种情况中的哪一种,只要取两种情况中的较小值就行。
我们要设计一个算法,它做的事是
- 记录下当前遍历过的字符串中的最长回文子串的回文中心(iMax),以及其回文半径(rMax)。回文半径就是回文长度除以二加一。
- 当得到 iMax 时,我们已经知道所有小于 iMax 的位置的回文信息
- 基于上面两步,求大于 iMax 的位置 i 的回文信息,
- 求出以 i 为回文中心的最大回文子串信息
- 用上一步得到信息,选择性地更新 iMax 以及 rMax
- 最后选出最大的 rMax ,最长回文子串的长度就是 rMax - 1
可以用一个数组记录以位置 i 为中心的回文长度: dp 。初始状态下,因为回文长度最小是 1,对每一个 i , 都有 dp[i] = 1 。
若 j 与 i 关于 iMax 对称,可以知道 j = 2 * iMax - i
下面是简单的程序实现:
let iMax = 0;
let rMax = 1;
const dp = Array(str.length).fill(1) // dp[i] 记录以位置 i 为中心的回文长度
for(let i = 0; i < str.length; i++) {
if(i > iMax && 2 * iMax - i >= 0) {
dp[i] = Math.min(dp[2 * iMax - i], iMax + rMax - i)
}
// 尝试去找以 i 为中心的回文子串
while(
i + dp[i] < str.length
&& i - dp[i] >= 0
&& str[i - dp[i]] === str[i + dp[i]])
{
dp[i]++
}
// 如果新的回文子串比原来的覆盖更远,就更新
if(i + dp[i] > iMax + rMax) {
iMax = i
rMax = dp[i]
}
}
虽然代码有两重循环,但是里层循环要满足回文条件。代码的时间复杂度平均来说是线性复杂度。
下面是完整代码:
const findLongestPalindrome = (str) => {
let len = str.length;
let max = 0;
const newStr = ['#']
for (let i = 0; i < len; i++) {
newStr.push(str[i])
newStr.push('#')
}
len = newStr.length
let iMax = 0;
let rMax = 1;
const dp = Array(len).fill(1)
for (let i = 0; i < len; i++) {
if (i > iMax && 2 * iMax - i >= 0) {
dp[i] = Math.min(dp[2 * iMax - i], iMax + rMax - i)
}
while (
i + dp[i] < len
&& i - dp[i] >= 0
&& newStr[i - dp[i]] === newStr[i + dp[i]])
{
dp[i]++
}
if (i + dp[i] > iMax + rMax) {
iMax = i
rMax = dp[i]
}
max = Math.max(max, rMax)
}
return max - 1
}
findLongestPalindrome('aba')
findLongestPalindrome('cddc')
findLongestPalindrome('abc')
findLongestPalindrome('usacdcuseless')
参考: